
Someone Else’s Cloud Broke Your Customer Support Again

By Prosanjit Dhar
February 19, 2026
Last Modified: February 23, 2026




Three platforms. Four outages. Millions in delayed resolutions.
And every single time, your customers paid the price for infrastructure you don’t own and can’t fix.
On October 20, 2025, support agents at thousands of companies opened their support dashboards and found nothing.
No tickets, no omnichannel routing, no access to customer history. Just a status page quietly updating while their queues grew and their customers waited.
The cause? A DNS race condition inside AWS US-East-1’s DynamoDB system. A latent bug in Amazon’s infrastructure had taken pods 19 and 23 completely offline.
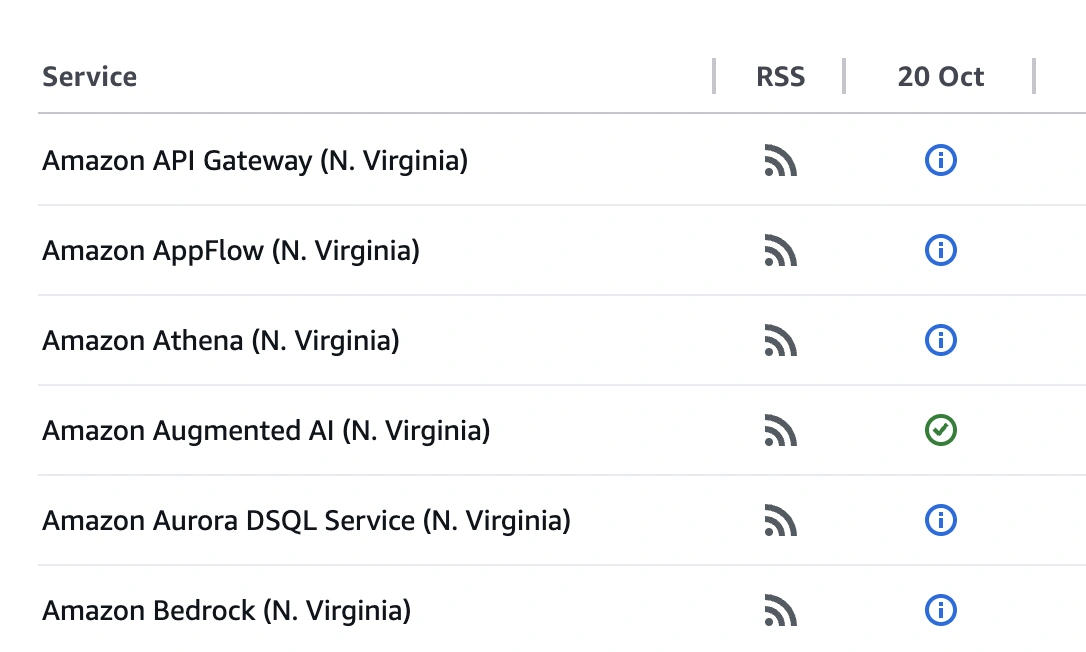
It lasted approximately 15 hours. The full AWS post is documented here. The Guardian reported an empty DNS record failure that cascaded across every service dependent on that region.
AWS is a massive cloud platform powering millions of businesses, but not every day is a perfect day.
This wasn’t a one-off; it was Tuesday
The October AWS incident is a clean and documented example of a problem that repeats with uncomfortable regularity.
Here’s what the last 13 months actually looked like:
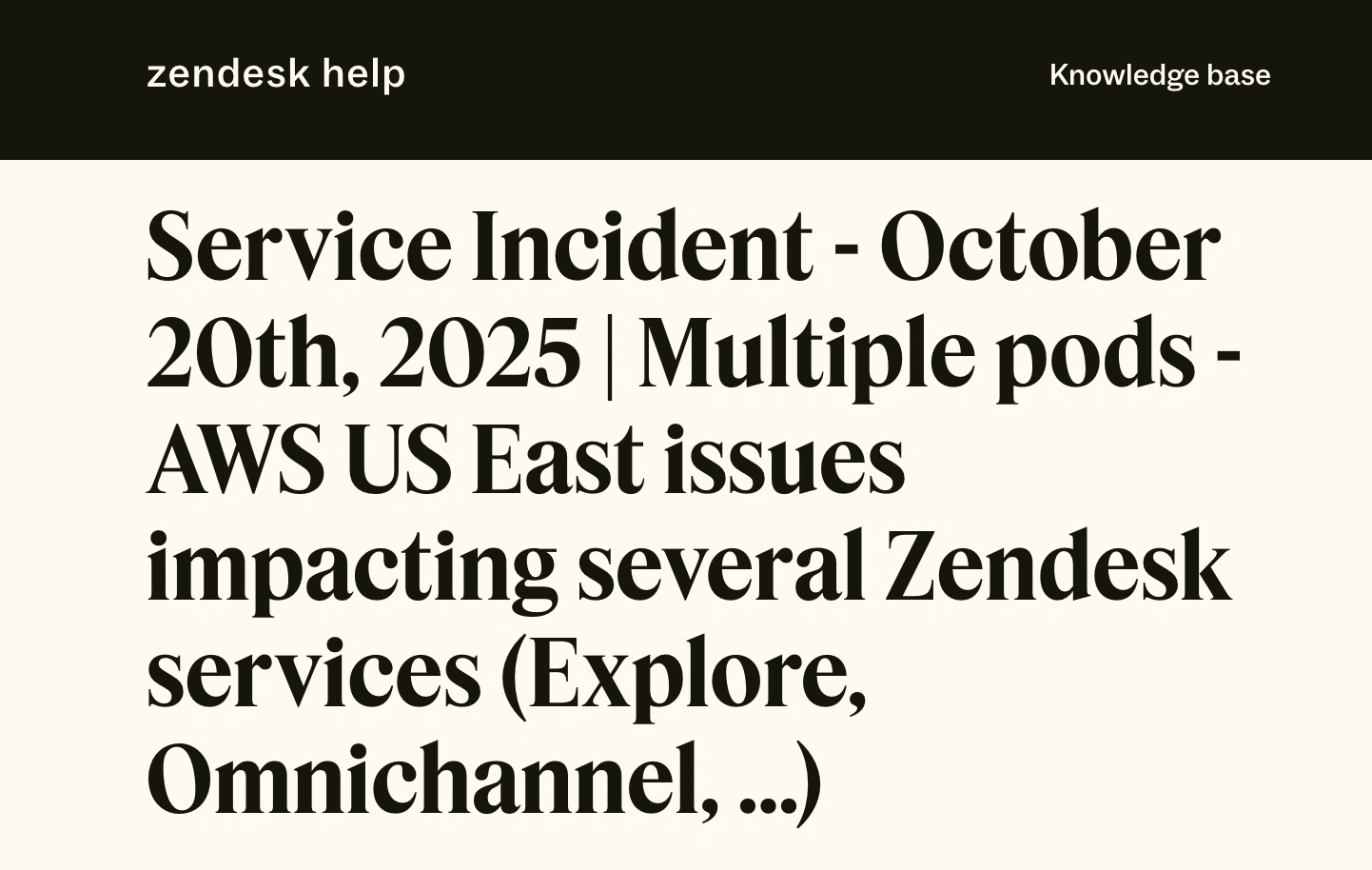
Oct 20, 2025 AWS US-East-1 DynamoDB DNS failure. ~15-hour outage. Zendesk pods 19 & 23 are frozen as ticketing is dead, omnichannel is dead, and agents are locked out.
↗ Zendesk incident report: Pods 19 & 23
↗ ThousandEyes AWS outage analysis
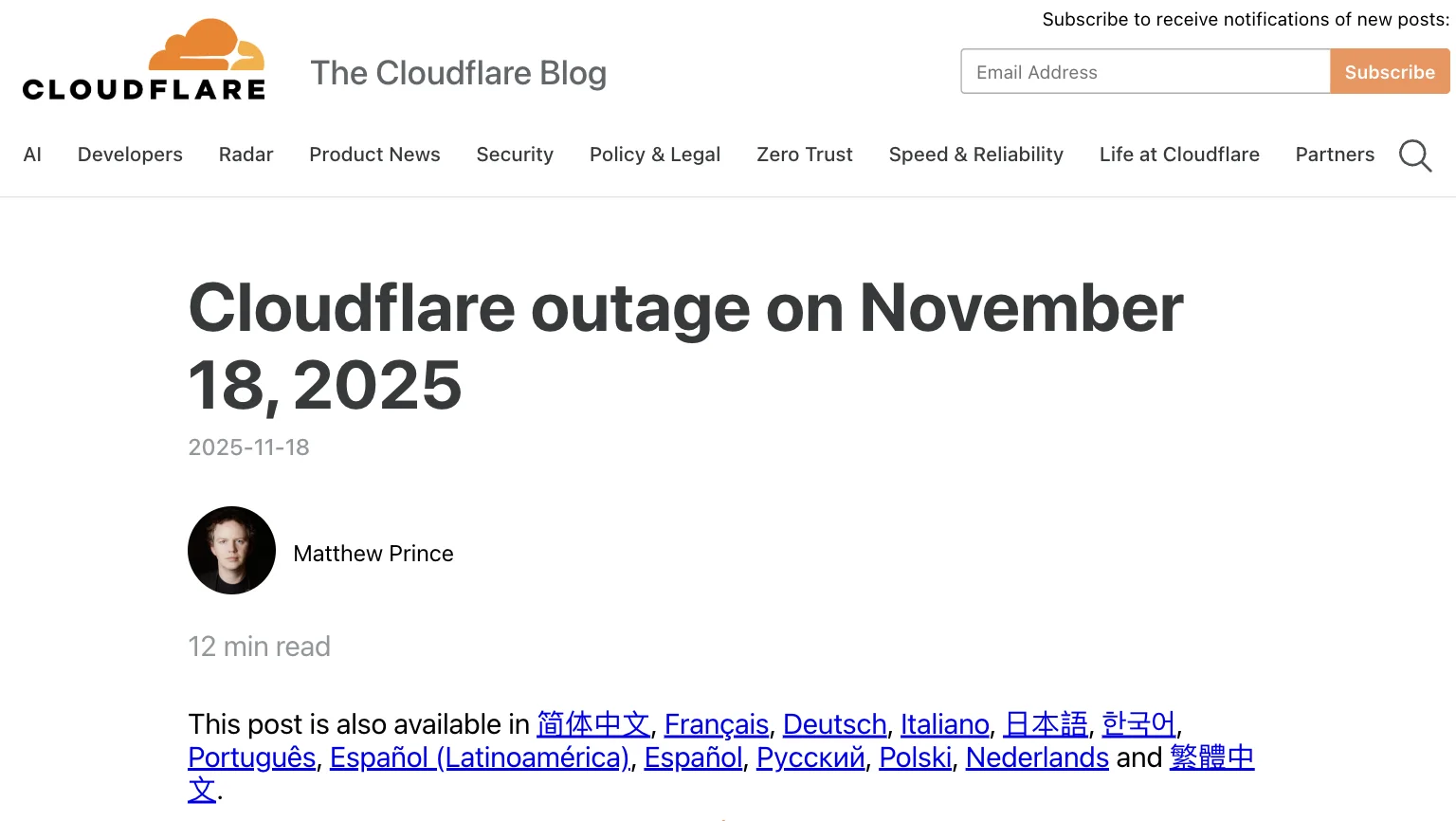
Nov 18, 2025, Cloudflare global multi-hour outage. A doubled configuration file from a database query error crashed proxies worldwide. Shopify, X, and ChatGPT went dark, and every support portal relying on Cloudflare for delivery went with them.

Jun 10–11, 2025 Salesforce 24-hour disruption. An automated OS update on Heroku hosts broke network routes. Service Cloud logins, APIs, and consoles are down across multiple clouds simultaneously.
↗ Salesforce official Incident report
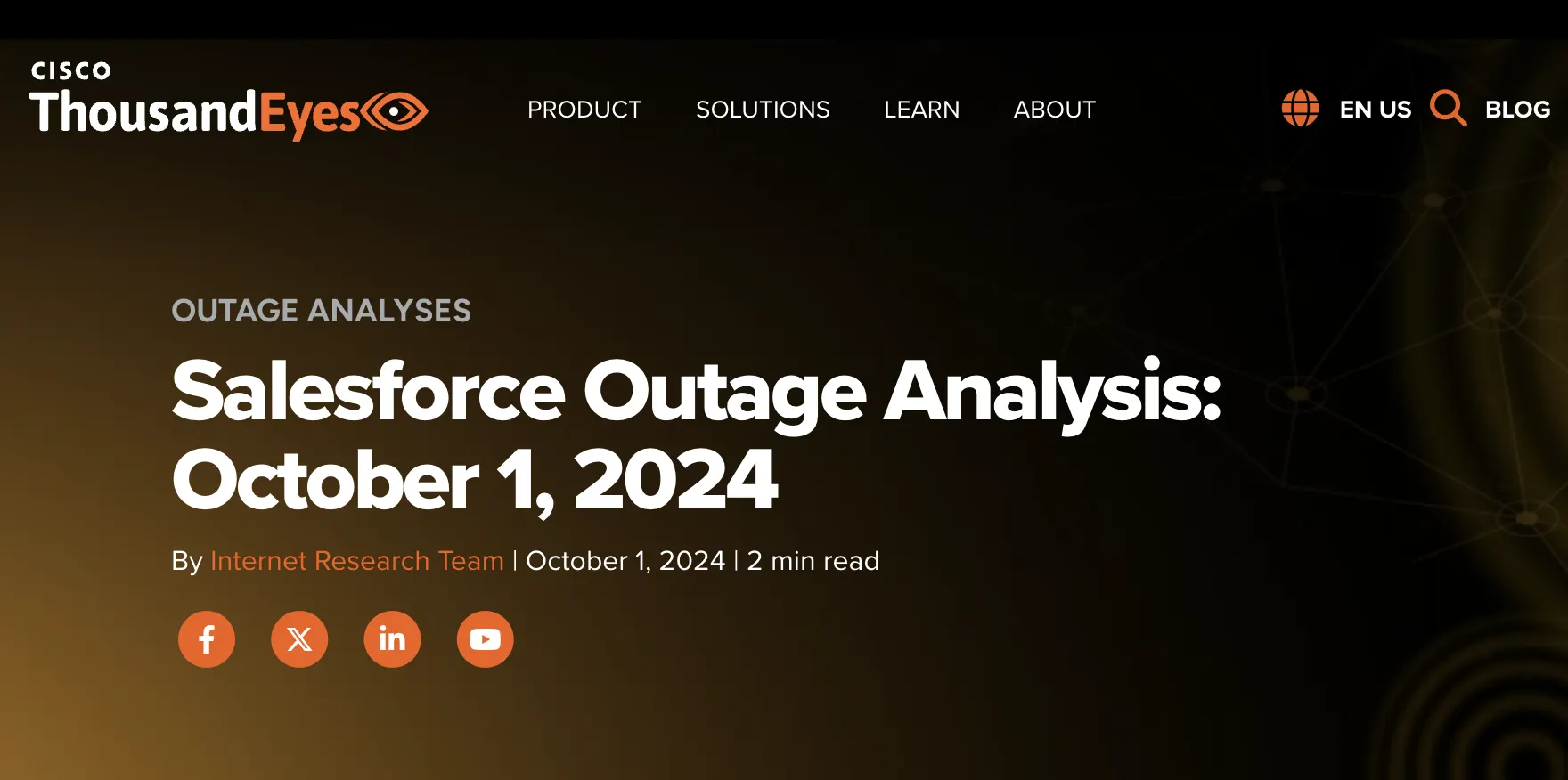
Oct 1–2, 2024 Salesforce again. A missing time-specific configuration caused core app timeouts and slow performance, blocking workflows for up to a full day.
↗ ThousandEyes’ Salesforce outage analysis

Nov 15, 2024 Salesforce database maintenance bug deleted critical objects. Permission failures across North America and Asian instances. Hours of broken assignment logic.
↗ Salesforce November 2024 report
Four separate platforms and five incidents. All within 13 months and all caused by infrastructure decisions made in data centers you’ve never visited, by engineers you’ve never met, running code you’ll never see.
The architecture was designed for them, not for you
Every major cloud-hosted support platform (Zendesk, Salesforce Service Cloud, Freshdesk) runs on a multi-tenant architecture. That means your account, your tickets, and your agents share infrastructure with thousands of other businesses.
When that infrastructure fails, it doesn’t fail for one customer. It fails for all of them at once. And that’s frightening.
Zendesk’s pod system is a good example. Pods are logical groupings of thousands of accounts on shared AWS infrastructure. Pod 19 going down on October 20 didn’t affect one company, but affected every company in that pod simultaneously. The failure radius is massive by design because the cost savings from shared infrastructure are massive by design.
You’re not renting a dedicated tool. You’re sharing one. And when it breaks, everyone who shares it breaks together.
This isn’t a criticism of these companies’ engineering teams. Multi-tenant cloud is how SaaS economics work at scale. But the trade-off is real. You get a lower monthly bill in exchange for shared failure risk. And in some cases, these aren’t even cheaper.
The bill doesn’t come from the platform; it comes from customers
Support SLAs don’t pause during vendor outages. Your customers don’t know that Zendesk is fighting AWS. They only know that it’s been four hours and nobody has replied.
The direct costs are measurable:
- Tickets pile up during the outage window, and agents can’t process what they can’t see.
- First response time metrics spike, and those spikes are often permanent in customer memory.
- Escalations increase, and customers who waited too long skip email entirely and go straight to chargebacks, social posts, or cancellations.
- An agent returning to a backlog after a multi-hour outage is not the same as a normal queue.
The indirect costs are harder to measure but easier to feel: trust erosion. Every support failure (regardless of cause) is attributed by the customer to you, not to your vendor’s infrastructure.
No customer has ever written a negative review about AWS DynamoDB. They write about the company that didn’t reply.
So, is there any solution to this type of crisis? Yes, definitely.
Your support desk doesn’t have to live in the cloud server
Fluent Support can be your alternative option. And we’re not just making claims; we’re giving you the facts.
First of all, it’s a self-hosted WordPress plugin. It installs in under five minutes and runs entirely on your own hosting infrastructure. As a result, all of your data stays on your server, under your control. So there’s no risk of being locked out of your own customer information.
Moreover, you’re free to choose any hosting provider you prefer. You can even host the email parser yourself, since it’s a fully open-source customer support system.
Fluent Support gives you full security, full ownership, and no data lock-in.
On October 20, 2025, while Zendesk pods 19 and 23 were offline and agents across the industry were staring at broken dashboards, every Fluent Support user’s helpdesk loaded every necessary information and also ran perfectly (unless the user’s server is hosted on AWS).
Not because Fluent Support has better SLAs for uptime. Because it isn’t hosted in the same place that failed.
Specifically, this matters in three scenarios:
- AWS US-East-1 goes down: Fluent’s dashboard runs on your host and stays unaffected.
- Cloudflare proxy crashes: Fluent doesn’t route support tickets through Cloudflare CDN infrastructure by default, and it is unaffected.
- Your SaaS vendor’s pod gets hit: Fluent has no pods, no multi-tenant infrastructure, no shared failure radius, so it is also unaffected.
The difference is that when your hosting fails, you have a direct relationship with the party responsible and full control over your recovery path.
That’s a fundamentally different situation than waiting for AWS to fix a DNS race condition in a DynamoDB Planner component you’ve never heard of.
Fluent Support runs on your own server. Not theirs.
The latency problem nobody talks about
For support teams in South Asia, Southeast Asia, and Africa, there’s a second layer to this problem that rarely gets covered.
Cloud-hosted platforms routing through US-East-1 introduce meaningful baseline latency before any outage occurs. Response times from Singapore to an AWS data center in Virginia are structurally higher than response times to a server hosted regionally. Every dashboard load, every ticket fetch, every AI draft call carries that geographic tax.
With Fluent Support on regional hosting, that tax disappears. Core ticketing, saved replies, and manual workflows run on your server end.
If OpenAI’s API is slow on a given day, AI features degrade gracefully, but the rest of the system keeps working. Your support desk doesn’t depend on a clean connection to a server on the other side of the planet to function.
Resilience isn’t only about outages. It’s about what works at 2 AM when the international connection is flaky, and your customer needs a reply.
Own what your customers depend on
Four outages in 13 months (AWS, Salesforce, Cloudflare). Platforms that collectively serve hundreds of millions of users, and run on infrastructure that is genuinely world-class.
And they still went down for hours repeatedly.
The lesson isn’t that cloud platforms are bad. The lesson is that the architecture you choose for your support infrastructure is a customer experience decision, not just a pricing or features decision.
When you self-host your helpdesk, you’re not betting against AWS. You’re just not betting on it, either.
Start off with a powerful ticketing system that delivers smooth collaboration right out of the box.
Related Articles
Customer Service Philosophy: Examples & Downloadable Template
Customer service philosophy is a documented set of…How IKEA Turned AI ‘Failures’ Into €1.3 Billion in Revenue
IKEA’s Billie chatbot handled 47% of call centre…






Leave a Reply